Pixicular vs AWS Rekognition
A developer-first comparison of pricing, features, and request models for image analysis and content moderation.
Published 2026-05-13

TL;DR. Pixicular and AWS Rekognition both offer managed image analysis, but they take different shapes. Rekognition is a feature-per-endpoint service billed per call inside AWS. Pixicular is a single POST endpoint that accepts a list of services — labels, moderation, age, OCR, face emotions — and returns one structured JSON response, on flat monthly plans. For multi-service workflows Pixicular is fewer network hops and easier to forecast.
How the two services line up
AWS Rekognition has been a default choice for image analysis on AWS-native stacks for years. It exposes a wide surface — DetectLabels, DetectFaces, DetectModerationLabels, DetectText, RecognizeCelebrities, Rekognition Video, Custom Labels — and integrates tightly with S3, IAM and EventBridge. Pixicular's image analysis API targets the same core jobs (labels, moderation, age, OCR, face emotion) but collapses them behind a single endpoint and a flat per-operation pricing model.
The table below summarises the differences that matter when you are picking between the two for a typical web or mobile backend.
Pricing and feature comparison
| Capability | Pixicular | AWS Rekognition |
|---|---|---|
| Comprehensive request history with image previews | Every API call is stored with an image preview, browsable in the dashboard and retrievable via the API — no extra logging or storage to wire up | Not offered — responses are not stored; you build your own request log and image archive |
| Pricing model | Flat monthly plans (Developer trial, $25, $99, $299) billed per AI operation | Pay-as-you-go per API call per feature, tiered by volume and region |
| Services per request | Many services in one call (labels + moderation + age + OCR + emotions) | One feature per endpoint — call each one separately |
| Label / object detection | detect-labels | DetectLabels |
| Content moderation | detect-moderation | DetectModerationLabels |
| Age estimation | detect-age (first-class service) | AgeRange attribute via DetectFaces |
| OCR / text extraction | detect-text | DetectText |
| Face emotion recognition | detect-face-emotions | Emotions attribute via DetectFaces |
| AI-generated image detection | Returning soon (currently disabled) | Not offered |
| Endpoints to wire up for a typical UGC pipeline | One: POST /detect | Three or more: DetectLabels, DetectModerationLabels, DetectFaces (+ optional DetectText) |
| Infrastructure footprint | Standalone API — no AWS account needed | Requires AWS account, IAM, and (typically) S3 for non-trivial workloads |
See the full plan ladder on the Pixicular pricing page. AWS publishes Rekognition rates on its own pricing pages and the AWS Free Tier page; rates vary by feature and region.
One call vs many calls
The single biggest day-to-day difference is request shape. AWS Rekognition is built around one feature per endpoint: if a profile photo needs to be checked for moderation flags, tagged with labels, and have an age range estimated, that is three independent API calls — three sets of request signing, three round trips, three sets of latency and error handling, and three line items on the bill.
Pixicular collapses that into one POST. The client uploads the image once and passes a comma-separated services parameter. The server fans the work out, waits for all requested services to finish, and returns a single JSON response. For pipelines that always need more than one service per image — moderation + labels for a marketplace listing, age + moderation for a dating profile, OCR + labels for an insurance claim — that shape is significantly less code.
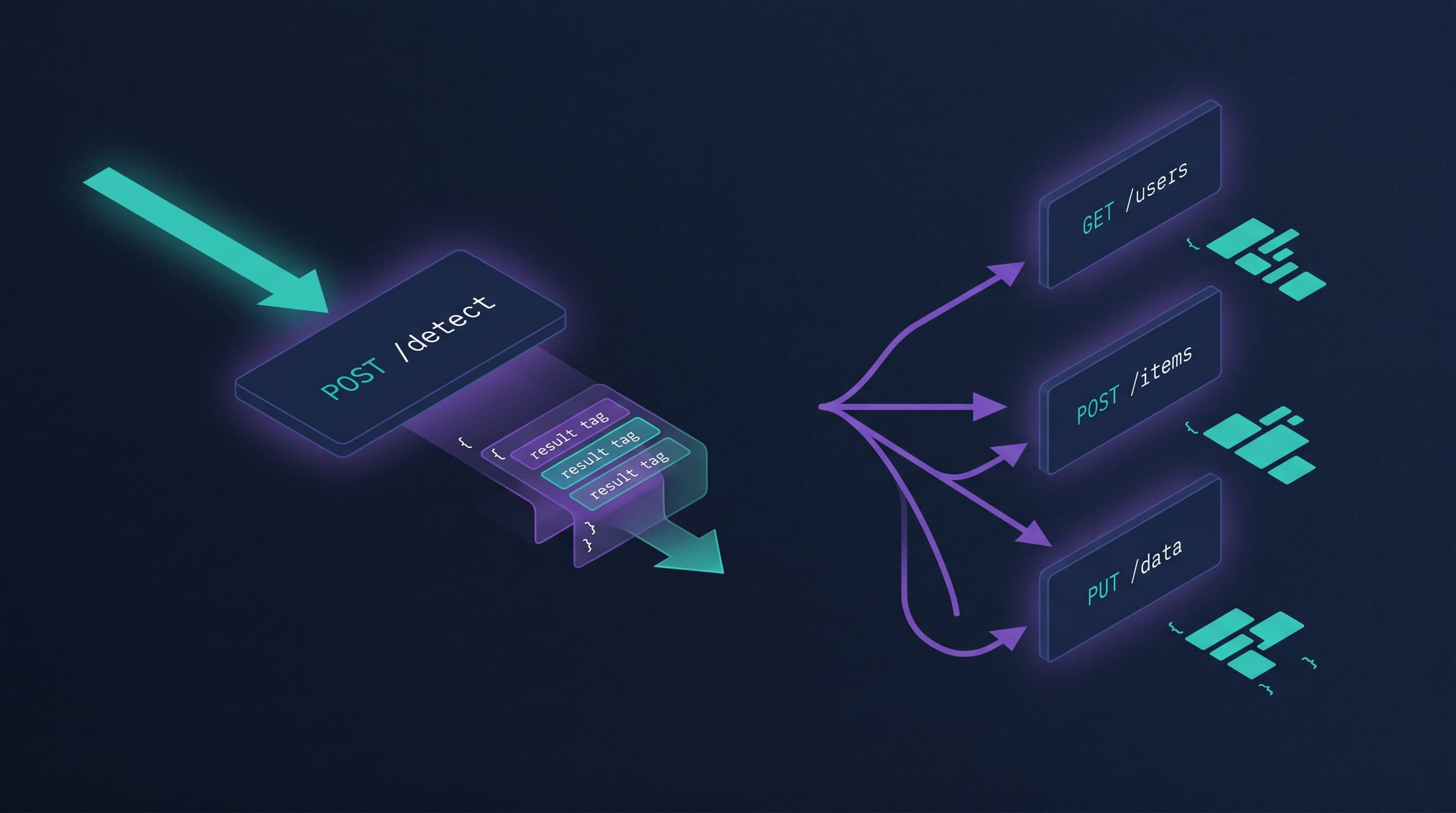
POST /detect returns every requested service in one JSON body. Right: feature-per-endpoint APIs require a fan-out and reassembly on the client.Code: labels + moderation + age in both APIs
Here is the same job — get label detection, content moderation, and age estimation for a single image — expressed in Pixicular and in AWS Rekognition.
Pixicular — one request
curl -X POST https://api.pixicular.com/detect \
-H "Authorization: Bearer $PIXICULAR_API_KEY" \
-F "image=@./photo.jpg" \
-F "services=detect-labels,detect-moderation,detect-age"The response is a single JSON document with one key per requested service. See the Pixicular API documentation for the full response schema and authentication details.
AWS Rekognition — three requests
# AWS Rekognition: three separate calls for the same result.
aws rekognition detect-labels \
--image '{"S3Object":{"Bucket":"my-bucket","Name":"photo.jpg"}}' \
--max-labels 20 --min-confidence 70
aws rekognition detect-moderation-labels \
--image '{"S3Object":{"Bucket":"my-bucket","Name":"photo.jpg"}}' \
--min-confidence 60
# Rekognition has no native age endpoint — read AgeRange from DetectFaces.
aws rekognition detect-faces \
--image '{"S3Object":{"Bucket":"my-bucket","Name":"photo.jpg"}}' \
--attributes ALLRekognition does not expose a dedicated age endpoint. To get an age estimate you call DetectFaces with --attributes ALL and read the AgeRange field on each detected face.
When to pick Pixicular
- Your pipeline regularly needs more than one service per image — for example, product image moderation for e-commerce or content moderation combined with age estimation.
- You want predictable monthly billing rather than per-feature, per-region metering.
- You are not on AWS, or you do not want to take on an AWS account, IAM policies and S3 staging just to add image moderation to an app.
- You need first-class age estimation rather than reaching for it via a face attribute.
- Your use case is closer to NSFW and nudity detection on still images than to video stream analysis or custom-classifier training.
When to stay on AWS Rekognition
Rekognition is the right pick when the rest of your stack is already AWS and you are leaning on S3 event notifications, EventBridge, Lambda or Step Functions to orchestrate analysis. It is also the right pick when you need Rekognition Video for stored and streaming video pipelines, or Custom Labels to train your own classifiers on domain-specific imagery. Pixicular focuses on still-image analysis and a smaller, opinionated set of services.
Note on AI-generated image detection: Pixicular's detection of AI-generated imagery is currently disabled while accuracy is being improved and is returning soon. AWS Rekognition does not offer an AI-generated-image detector either. If that signal is essential to your product today, both services will need to be paired with a specialist provider.
Frequently asked questions
Is Pixicular a drop-in replacement for AWS Rekognition?
Pixicular covers most of the core image-analysis surface developers reach for in AWS Rekognition: label detection, content moderation, age estimation, face emotion recognition, and OCR. The request and response shapes differ — Pixicular uses a single endpoint that accepts a list of services and returns one JSON blob — so it is not a literal drop-in, but for many applications the migration is a thin adapter rather than a rewrite. AI-generated image detection is currently disabled in Pixicular and is returning soon.
How does Pixicular's pricing compare to AWS Rekognition?
Pixicular bills per AI operation in flat-rate monthly plans, with the trial Developer plan free for 14 days, Launch at $25/month, Scale at $99/month, and Business at $299/month. AWS Rekognition bills per API call per feature with a tiered per-1,000-image rate that varies by feature and region. Because a single Pixicular call can return labels, moderation, age and OCR together, the per-image cost for multi-service workflows is typically lower and easier to forecast.
Does Pixicular support content moderation like Rekognition?
Yes. Pixicular's detect-moderation service returns flags and confidence scores across categories including nudity, explicit sexual content, violence, and suggestive material. It is intended to cover the same UGC, e-commerce and marketplace screening use cases that teams currently solve with Rekognition's DetectModerationLabels endpoint.
Can I detect age with Pixicular like with Rekognition?
Yes — and more directly. AWS Rekognition does not have a dedicated age endpoint; you call DetectFaces and read the AgeRange attribute from each face. Pixicular exposes detect-age as a first-class service that returns an age estimate per face in the same JSON response as any other service you request, with no extra plumbing.
Where does AWS Rekognition still have an edge?
Rekognition is the right choice when you need deep AWS-native integration (IAM, S3 event triggers, EventBridge), Rekognition Video for stored-video and streaming analysis, Custom Labels for training your own classifiers, or workloads pinned to a specific AWS region for compliance. Pixicular focuses on still images and a smaller, opinionated surface area that ships faster to integrate.
Try the single-endpoint model
The fastest way to see whether Pixicular fits your image pipeline is to point a curl request at it. Start on the pricing page to pick a plan, then follow the API documentation for authentication, request shape, and JSON response examples for each service.